Once a site is live or has advanced past a certain age, most webmasters don’t really concern themselves with their crawl budget anymore.
As long as you keep linking to new blog posts at some point in your website, it should simply show up in Google or Bing’s index and start ranking.
Only, after time, you notice that your site is starting to lose keyword rankings and none of your new posts are even hitting the top 100 for their target keyword.
It could simply be a result of your site’s technical structure, thin content, or new algorithm changes, but it could also be caused by a very problematic crawl error.
With hundreds of billions of webpages in Google’s index, you need to optimize your crawl budget to stay competitive.
Here are 11 tips and tricks to help optimize your crawl speed and help your webpages rank higher in search.
1. Track Crawl Status with Google Search Console
Errors in your crawl status could be indicative of a deeper issue on your site.
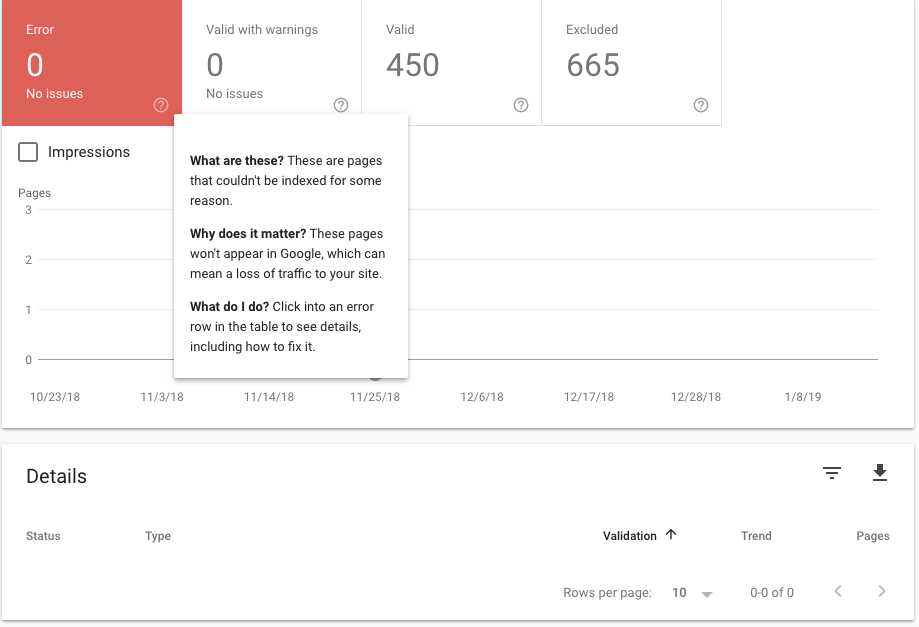
Checking your crawl status every 30-60 days is important to identify potential errors that are impacting your site’s overall marketing performance. It’s literally the first step of SEO; without it, all other efforts are null.
Right there on the sidebar, you’ll be able to check your crawl status under the index tab.
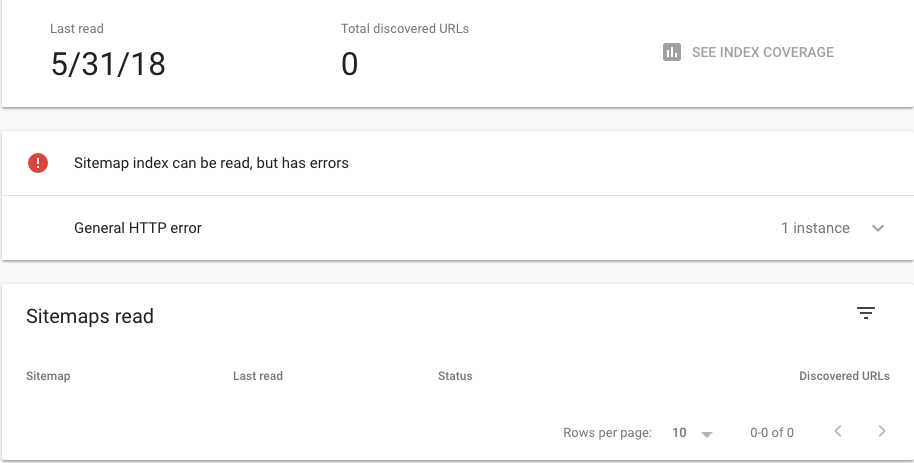
Now, if you want to remove access to a certain webpage, you can tell Search Console directly. This is useful if a page is temporarily redirected or has a 404 error.
A 410 parameter will permanently remove a page from the index, so beware of using the nuclear option.
Common Crawl Errors & Solutions
If your website is unfortunate enough to be experiencing a crawl error, it may require an easy solution or be indicative of a much larger technical problem on your site. The most common crawl errors I see are:
- DNS errors
- Server errors
- Robots.txt errors
- 404 errors

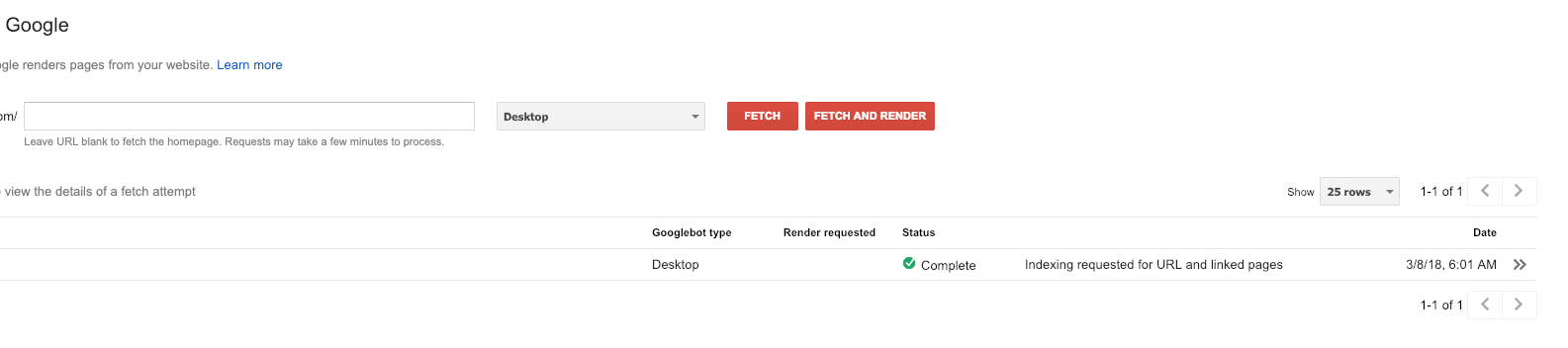
To diagnose some of these errors, you can leverage the Fetch as Google tool to see how Google effectively views your site.
Failure to properly fetch and render a page could be indicative of a deeper DNS error that will need to be resolved by your DNS provider.
Resolving a server error requires diagnosing a specific error that can be referenced in this guide. The most common errors include:
- Timeout
- Connection refused
- Connect failed
- Connect timeout
- No response
Most of the time, a server error is usually temporary, although a persistent problem could require you to contact your hosting provider directly.
Robots.txt errors, on the other hand, could be more problematic for your site. If your robots.txt file is returning a 200 or 404 error, it means search engines are having difficulty retrieving this file.
You could submit a robots.txt sitemap or avoid the protocol altogether, opting to manually noindex pages that could be problematic for your crawl.
Resolving these errors quickly will ensure that all of your target pages are crawled and indexed the next time search engines crawl your site.
2. Create Mobile-Friendly Webpages
With the arrival of the mobile-first index, we must also optimize our pages to display mobile friendly copies on the mobile index.
The good news is that a desktop copy will still be indexed and display under the mobile index if a mobile-friendly copy does not exist. The bad news is that your rankings may suffer as a result.
There are many technical tweaks that can instantly make your website more mobile friendly including:
- Implementing responsive web design.
- Inserting the viewpoint meta tag in content.
- Minifying on-page resources (CSS and JS).
- Tagging pages with the AMP cache.
- Optimizing and compressing images for faster load times.
- Reducing the size of on-page UI elements.
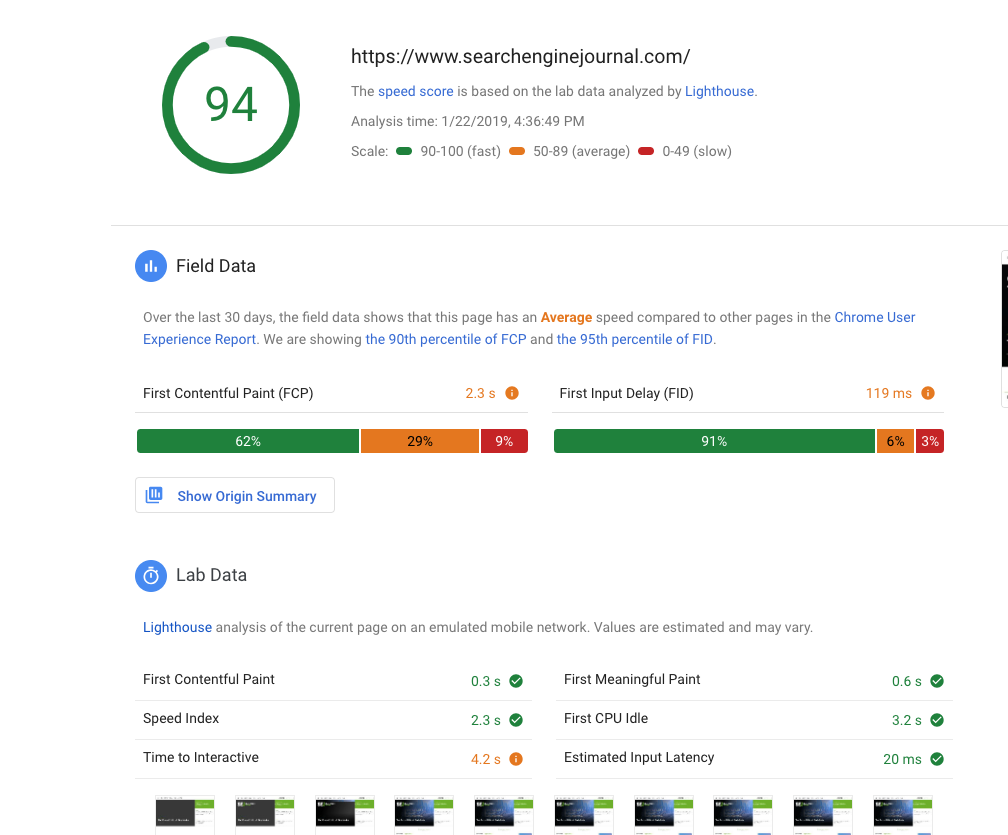
Be sure to test your website on a mobile platform and run it through Google Pagespeed Insights. Page speed is an important ranking factor and can affect the speed to which search engines can crawl your site.
3. Update Content Regularly
Search engines will crawl your site more regularly if you produce new content on a regular basis. This is especially useful for publishers who need new stories published and indexed on a regular basis.
Producing content on a regular basis signals to search engines that your site is constantly improving and publishing new content and therefore needs to be crawled more often to reach its intended audience.
4. Submit a Sitemap to Each Search Engine
One of the best tips for indexation to this day remains submitting a sitemap to Google Search Console and Bing Webmaster Tools.
You can create an XML version using a sitemap generator or manually create one in Google Search Console by tagging the canonical version of each page that contains duplicate content.
5. Optimize Your Interlinking Scheme
Establishing a consistent information architecture is crucial to ensuring that your website is not only properly indexed, but also properly organized.
Creating main service categories where related webpages can sit can further help search engines properly index webpage content under certain categories when intent may not be clear.
6. Deep Link to Isolated Webpages
If a webpage on your site or a subdomain is created in isolation or there is an error preventing it from being crawled, then you can get it indexed by acquiring a link on an external domain. This is an especially useful strategy for promoting new pieces of content on your website and getting it indexed quicker.
Beware of syndicating content to accomplish this as search engines may ignore syndicated pages and it could create duplicate errors if not properly canonicalized.
7. Minify On-Page Resources & Increase Load Times
Forcing search engines to crawl large and unoptimized images will eat up your crawl budget and prevent your site from being indexed as often.
Search engines also have difficulty crawling certain backend elements of your website. For example, Google has historically struggled to crawl JavaScript.
Even certain resources like Flash and CSS can perform poorly over mobile devices and eat up your crawl budget. In a sense, it’s a lose-lose scenario where page speed and crawl budget are sacrificed for obtrusive on-page elements.
Be sure to optimize your webpage for speed, especially over mobile, by minifying on-page resources, such as CSS. You can also enable caching and compression to help spiders crawl your site faster.
8. Fix Pages with Noindex Tags
Over the course of your website’s development, it may make sense to implement a noindex tag on pages that may be duplicated or only meant for users who take a certain action.
Regardless, you can identify web pages with noindex tags that are preventing them from being crawled by using a free online tool like Screaming Frog.
The Yoast plugin for WordPress allows you to easily switch a page from index to noindex. You could also do this manually in the backend of pages on your site.
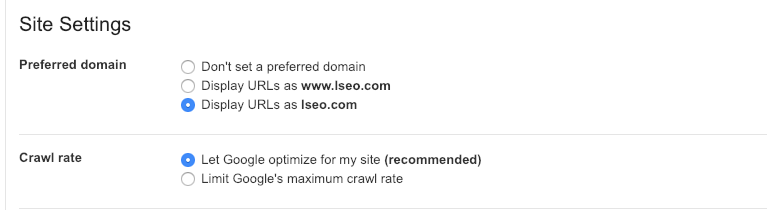
9. Set a Custom Crawl Rate
In the old version of Google Search Console, you can actually slow or customize the speed of your crawl rates if Google’s spiders are negatively impacting your site.
This also gives your website time to make necessary changes if it is going through a significant redesign or migration.
10. Eliminate Duplicate Content
Having massive amounts of duplicate content can significantly slow down your crawl rate and eat up your crawl budget.
You can eliminate these problems by either blocking these pages from being indexed or placing a canonical tag on the page you wish to be indexed.
Along the same lines, it pays to optimize the meta tags of each individual page to prevent search engines from mistaking similar pages as duplicate content in their crawl.
11. Block Pages You Don’t Want Spiders to Crawl
There may be instances where you want to prevent search engines from crawling a specific page. You can accomplish this by the following methods:
- Placing a noindex tag.
- Placing the URL in a robots.txt file.
- Deleting the page altogether.
This can also help your crawls run more efficiently, instead of forcing search engines to pour through duplicate content.
Conclusion
Chances are, if you are already following SEO best practices, you should have nothing to worry about with your crawl status.
Of course, it never hurts to check your crawl status in Google Search Console and to conduct a regular internal linking audit.
Source: This article was originally posted at Search Engine Journal by Kristopher Jones on January 24, 2019